1. 라이브러리 임포트
pandas를 `pd`, numpy를 `np`, seaborn을 `sns`, matplotlib.pyplot을 `plt`로 임포트하세요.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. 데이터 불러오기
auto_mpg.xlsx 파일을 불러와 mpg_df 데이터프레임을 생성합니다.
- pandas를 이용하여 파일을 읽고 `mpg_df`에 저장하세요.
mpg_df = pd.read_excel('auto_mpg.xlsx')
mpg_dfpd.read_excel
3. 컬럼명 변경
영어로 되어져 있는 컬럼명을 한글로 수정하고자 합니다.
컬럼명 변경 조건
- mpg 연비
- cylinders = 실린더 수
- displacement = 배기량
- horsepower = 마력
- weight = 차량 무게
- acceleration = 가속 성능
- model_year = 차량 출시 연도
- origin = 제조 국가 코드
- name = 차량 이름
inplace = True
mpg_df.rename(columns={
'mpg': '연비',
'cylinders': '실린더 수',
'displacement': '배기량',
'horsepower': '마력',
'weight': '차량 무게',
'acceleration': '가속 성능',
'model_year': '차량 출시 연도',
'origin': '제조 국가 코드',
'name': '차량 이름'
}, inplace=True).rename ( columns = { '전' : '후', '전2': '후2' } , inplace=True )
따옴표
4. 결측치 확인 및 처리
전체 컬럼에 대한 결측치를 확인하는 코드를 이용하여, 결측치를 처리하세요.
- 결측치가 존재하는 해당 행 삭제
- 처리한 데이터는 del_df 변수에 저장
del_df = mpg_df.dropna().dropna(괄호 있음)
5. 이상치 제거
마력과 연비에 대한 그래프를 확인하고 이상치를 제거하고자 합니다.
- 아래 셀을 실행하여 scatterplot을 확인하세요.
sns.scatterplot(data=del_df, x='마력', y='연비')sns.scatterplot(data=del_df, x='마력', y='연비')
위의 그래프를 보면 이상치가 존재한다는 것을 확인할 수 있습니다.
- 마력이 150이상이면서 연비가 50 초과하는 이상치를 제거하세요.
- inplace= True
del_df.drop(del_df[(del_df['마력'] >= 150) & (del_df['연비'] > 50)].index, inplace=True)
del_df = del_df.drop(del_df[(del_df['마력'] >= 150) & (del_df['연비'] > 50)].index)방법1. inplace=True 사용
del_df.drop ( del_df [ 조건 ].index, inplace = True )
[ 조건 ] = ( 조건1 ) & ( 조건 2 ) * 괄호 중요
( del_df['마력'] >= 150 ) & ( del_df['연비'] > 50 )
del_df.drop(del_df[(del_df['마력'] >= 150) & (del_df['연비'] > 50)].index, inplace=True)
방법2. 바로 df 변수에 할당
del_df = del_df.drop( del_df [조건].index )
[ 조건 ] = ( 조건1 ) & ( 조건 2 ) * 괄호 중요
( del_df['마력'] >= 150 ) & ( del_df['연비'] > 50 )
del_df = del_df.drop(del_df[(del_df['마력'] >= 150) & (del_df['연비'] > 50)].index)
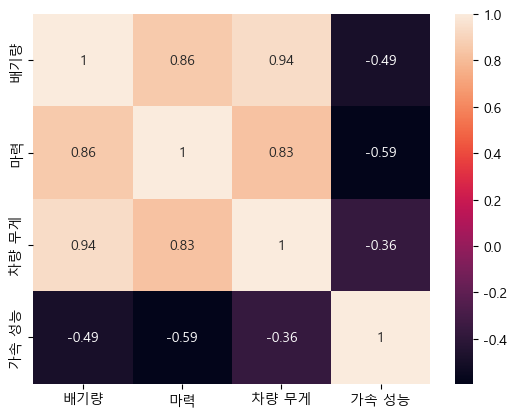
6. 연속형 변수 상관 관계 해석
- seaborn의 heatmap을 이용하여 변수들 간의 상관 관계 그래프를 그리세요.
- 가장 적절한 해석을 답06 변수에 저장하세요.
1. 배기량과 차량 무게는 함께 사용하는 것이 일반적이므로 모두 유지한다.
2. 마력과 배기량은 상관계수가 낮으므로 배기량을 남기고 마력을 제거한다.
3. 배기량과 차량 무게는 높은 상관관계를 가지므로, 예측력이나 변수 중요도를 고려하여 차량 무게를 제거한다.
4. 모든 변수는 예측력이 있으므로, 상관관계에 관계없이 모두 사용하는 것이 바람직하다.
- 아래 리스트를 이용하여 히트맵을 그리세요.
sns.heatmap(data=del_df[col_list].corr(), annot=True)
답06 = 3sns.heatmap(data=del_df[col_list].corr(), annot=True)
답06 = 3
보통 상관계수가 0.8 이상이면 "높은 상관관계" / 0.4 ~ 0.6 이면 "약한 상관관계"
상관관계가 높다 = 다중공선성 문제 = 둘 중 하나만 가지고 모델 돌린다
7. 불필요 컬럼 제거
예측 모델의 성능을 높이기 위해 불필요한 변수들을 제거하고자 합니다.
- 문제 6번에서 선택한 보기에 따라 다중공선성이 우려되는 변수를 제거합니다.
- 여기에 더해 다음의 3개 변수도 함께 제거하세요: '차량 출시 연도', '제조 국가 코드', '차량 이름'
- 단, 문제 6번에서 선택한 변수를 유지하기로 했다면, 위 3개 컬럼만 제거합니다.
- 처리된 데이터는 clear_df 변수에 저장
clear_df = del_df.drop(['차량 무게', '차량 출시 연도', '제조 국가 코드', '차량 이름'], axis=1)
clear_df앞서 답06 = 3 에 따라, ["차랑 무게"] 제거
여러 컬럼 삭제 시 [ '컬1', '컬2', '컬3', ... ]
8. 범주형 변수 인코딩
실린더 수 컬럼을 get_dummies로 변환하세요.
- drop_first=True 옵션 사용
- 처리된 데이터는 encoding_df 변수에 저장하세요.
encoding_df = pd.get_dummies(data=clear_df, columns=['실린더 수'], drop_first=True)
encoding_df = pd.get_dummies(data=clear_df, columns=['실린더 수'], drop_first=True)
9. train / test 데이터 분리
train_test_split을 이용하여 데이터를 분리하려고 합니다.
- Feature: 연비 컬럼 제외 전부
- Target: 연비
- 데이터셋을 분리하기 위해 train_test_split을 import하세요.
- 훈련 데이터 셋 = X_train, y_train
- 검증 데이터 셋 = X_valid, y_valid
- random_state=42
- 훈련 데이터셋과 검증 데이터셋의 비율은 8:2
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(encoding_df.drop(columns='연비'), encoding_df['연비'], test_size=0.2, random_state=42)from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(encoding_df.drop(columns='연비'), encoding_df['연비'], test_size=0.2, random_state=42)
10. 데이터 표준화
데이터 스케일링을 통해 모델 학습의 성능을 높입니다.
- StandardScaler를 이용해 Feature 데이터를 스케일링하세요.
- X_train은 fit_tranform을 이용하여 X_train 변수에 저장
- X_valid는 transform을 이용하여 X_test의 변수에 저장
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_valid)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_valid)
11. 서포트 벡터 머신(SVM) 모델 학습
서포트 벡터 머신(SVM)을 활용하여 연비를 예측합니다.
- SVR 모델은 svr 변수에 저장하세요.
- kernel='rbf', C=1.0, epsilon=0.2
- 훈련은 스케일링 처리된 데이터를 사용해 주세요.
from sklearn.svm import SVR
svr = SVR(kernel='rbf', C=1.0, epsilon=0.2)
svr.fit(X_train, y_train)from sklearn.svm import SVR
svr = SVR(kernel='rbf', C=1.0, epsilon=0.2)
svr.fit(X_train, y_train)
12. 랜덤 포레스트 회귀 모델 학습
랜덤포레스트 모델을 활용하여 연비를 예측합니다.
- 랜덤포레스트모델을 rfr변수에 저장하세요.
- n_estimators=200, max_depth=10, min_samples_split=7, random_state=42
- 훈련은 스케일링 처리된 데이터를 사용해 주세요.
from sklearn.ensemble import RandomForestRegressor
rfc = RandomForestRegressor(n_estimators=200, max_depth=10, min_samples_split=7, random_state=42)
rfc.fit(X_train,y_train)from sklearn.ensemble import RandomForestRegressor
rfc = RandomForestRegressor(n_estimators=200, max_depth=10, min_samples_split=7, random_state=42)
rfc.fit(X_train,y_train)
13. 딥러닝 모델 설계 및 학습
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
tf.random.set_seed(42)모델 구조
- `Dense(32, activation='tanh')` → `Dropout(0.3)`
- `Dense(24, activation='tanh')` → `Dropout(0.3)`
- `Dense(16, activation='tanh')`
- `Dense(8, activation='tanh')`
- `Dense(1, activation='linear')`
학습 설정
- Optimizer: `rmsprop`
- Loss: `mean_absolute_error`
- Metric: `mean_squared_error`
- Epochs: `50`
- Batch size: `8`
# 1. 모델 생성 + 레이어 묶기
model = Sequential([
Dense(units=32, 'tanh'),
Dropout(0.3),
Dense(units=24, 'tanh'),
Dropout(0.3),
Dense(units=16, 'tanh'),
Dense(units=8, 'tanh'),
Dense(units=1, 'linear')
])
# 2. 컴파일
model.compile(
optimizer='rmsprop',
loss='mean_absolute_error',
metrics=['mean_squared_error']
)
# 3. 학습
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=8
)
# 1. 모델 생성 + 레이어 묶기
model = Sequential([
Dense(units=32, 'tanh'),
Dropout(0.3),
Dense(units=24, 'tanh'),
Dropout(0.3),
Dense(units=16, 'tanh'),
Dense(units=8, 'tanh'),
Dense(units=1, 'linear')
])
# 2. 컴파일
model.compile(
optimizer='rmsprop',
loss='mean_absolute_error',
metrics=['mean_squared_error']
)
# 3. 학습
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=8
)
14. 딥러닝 모델을 이용한 시뮬레이션 예측
딥러닝 모델을 이용해 새로운 데이터를 예측합니다.
- `simul_data`를 모델에 입력하기 전에, 학습 시 사용한 `StandardScaler`의 `transform()`을 사용하여 동일하게 스케일링하세요.
- 스케일링된 결과를 `deep_pre` 변수에 저장하세요.
- `simul_data`는 원본 입력값이므로 반드시 스케일링을 적용한 후 예측에 사용해야 합니다.
simul_data = scaler.transform(simul_data)
deep_pre = model.predict(simul_data)
deep_presimul_data = scaler.transform(simul_data)
deep_pre = model.predict(simul_data)
예측 .predict
출처: 내돈내산 문제집

[이패스코리아] 2025 이패스 AI능력시험 AICE Associate /사은품 마스크제공 - 컴퓨터 입문/활용 | 쿠팡
쿠팡에서 [이패스코리아] 2025 이패스 AI능력시험 AICE Associate /사은품 마스크제공 구매하고 더 많은 혜택을 받으세요! 지금 할인중인 다른 컴퓨터 입문/활용 제품도 바로 쿠팡에서 확인할 수 있습
www.coupang.com